Chapter 5: The Nature of Reinforcement & Its Effects On Acquisition(1)
Overview: In the four major sections of this chapter,
we examine various approaches to evaluating what a reinforcer is, and what
role it plays in learning. The first section presents what might be termed
intrinsic reinforcement theories. This section is primarily devoted
to Hull's Drive Reduction Theory of reinforcement, but also discusses
Sheffield's Consummatory Response Hypothesis. Both theories discuss
biological approaches to reinforcement. Next, the second section discusses
what might be termed contextual reinforcement theories. Here, whether
something counts as a reinforcer varies with the individual situation facing
the animal; under certain circumstances, an event that reinforces in one
situation will fail to reinforce in another, in contrast to Skinner's claim
that reinforcement ought to be transsituational. Theories presented in
this section include Optimal Stimulation Theory, the Premack
Principle, and Timberlake and Allison's Equilibrium Theory.
The third section addresses theories that claim reinforcement is not
needed for learning. At issue in this section is why reinforcement seems
to influence the course of acquisition. Guthrie's Contiguity Theory
is discussed here, along with more cognitive approaches arising from Tolman's
work. In particular, this section examines associational versus
expectancy theories of avoidance learning. Finally, the last section
briefly visits the issue of expectancy-based versus habit-based behavior.
I. Intrinsic Reinforcement Theories
There have been a number of
theories over the years concerning the nature of reinforcement. In the
previous chapter, we saw a strictly definitional theory in the work of
Skinner: Reinforcement is whatever has an effect. That is an unsatisfactory
approach for most people, and there have correspondingly been attempts
to explore and explain the operation of reinforcement. In this section,
we start with a claim that is a bit like Skinner's: A reinforcer exists
as such independently of the animal's response or internal states. Some
stimuli qualify as reinforcers just as some stimuli have the property of
being red. In this sense, reinforcement is an intrinsic, unmutable property
of an event, and the question to ask is whether we can identify any inherent
feature that determines whether an event will have this property of reinforcement.
We start with a venerable claim by Hull that ties reinforcement to important
biological states.
A. Hull's Drive Reduction Theories
Hull published a complex theory
of learning in 1943 that underwent considerable development in the following
decade, as numerous researchers explored the claims of the earlier theory
and found objections to it. In that sense, he may actually be credited
with several different theories. Like Tolman, he built a system
based on intervening variables that serve as hypothetical links
between independent variables such as the amount of time a rat has
been deprived of food, and dependent variables such as the speed
with which the rat runs an alley to a goal box. He described a complex
system of principles couched in terms of these intervening variables. The
principles were used to make new predictions about how animals ought to
learn or behave. To the extent that these predictions were confirmed, the
intervening variables and their interrelationships that sanctioned these
predictions were justified. To the extent that the predictions were disconfirmed,
the interrelationships were modified, sometimes by the positing of yet
further intervening variables.
Before discussing some of
these intervening variables and principles, however, let us point out some
important preliminary assumptions of the theory. The first of these is
that the theory is a reinforcement theory: Learning requires
the presence of a reinforcer following a response. The second is that this
is a molecular response theory: What gets acquired is one or more
peripheral muscle movements, in contrast to Skinner's functional
definition of a response. The third is that this is an associational
S-R theory: Learning involves modifying the strength of the association
between a stimulus and a molecular response (or chain of molecular
responses in the case of complex behavior such as navigating a maze). The
fourth is that learning is incremental or continuous: The
association between a stimulus and response strengthens with each additional
reinforcer, rather than being all or none. Fifth, Hull's theory
posits permanent learning: An association can stay as it is or strengthen;
it will never weaken. And sixth, what appears to be inhibition (in
extinction, for example) is also due to an association that strengthens
because of the presence of a reinforcer. This last assumption, of course,
arises as a special case of the initial assumption that all learning
involves reinforcement.
Initial Formulation Of The Theory
Let us start with some terminology.
The notion of strength of the association is one of the important
intervening variables in this theory. Obviously, it implies that (1) there
is an association, and (2) that the association can vary
in strength. For Hull, the technical term for an association is a habit.
Habit strength is then symbolized by the variable SHR.
Intervening variables in Hull's system will often have subscript Ss
and Rs to indicate that the variable involves a relationship between
a stimulus and a response.
Habit strength will always
be 0 or greater. In the theory, each additional reinforcer will increase
the habit strength by an increment. The formula for determining the amount
of habit strength as a function of number of reinforced trials is:
SHR = 1 - 10-iN
In this formula, i is a rate parameter that refers to the individual
learning speed of a given animal, and N is the number of continuously
reinforced trials. Hull did measure the individual learning speed in one
experiment, and found it to be .0305, but he clearly held out the possibility
that it would be a different number with different individuals. Using the
.0305 parameter, we would expect that the learning curve over 20 trials
ought to be identical to the bottom (solid) line in Figure 1. As you can
see from this figure, the formula correctly predicts the general shape
of the acquisition curve as being negatively accelerated (i.e.,
a diminishing returns curve).
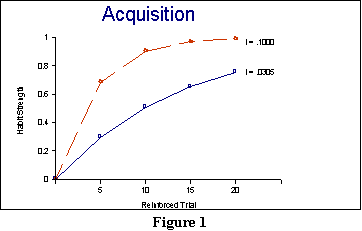 Another feature of this graph is noteworthy: The maximum value for habit
strength will be equal to 1. However, we may modify this formula slightly
to illustrate its similarity with the Rescorla-Wagner delta rule.
Thus, if we multiply a lambda by (1 - 10-iN),
then we see that both rules have a mechanism for evaluating how much of
the remaining association gets conditioned on each additional trial.
There is, of course, no variable for CS salience in Hull's formula. If
you recall, CS salience in the delta rule determined how rapidly
the curve approached asymptote. In contrast, the individual rate parameter
i determines the speed with which asymptote is approached in Hull's
formula. You can see this graphically by comparing the two lines in Figure
1. The top line corresponds to an i value of .1, and the result
is a much quicker approach to asymptote than when the i value is
smaller.
Another feature of this graph is noteworthy: The maximum value for habit
strength will be equal to 1. However, we may modify this formula slightly
to illustrate its similarity with the Rescorla-Wagner delta rule.
Thus, if we multiply a lambda by (1 - 10-iN),
then we see that both rules have a mechanism for evaluating how much of
the remaining association gets conditioned on each additional trial.
There is, of course, no variable for CS salience in Hull's formula. If
you recall, CS salience in the delta rule determined how rapidly
the curve approached asymptote. In contrast, the individual rate parameter
i determines the speed with which asymptote is approached in Hull's
formula. You can see this graphically by comparing the two lines in Figure
1. The top line corresponds to an i value of .1, and the result
is a much quicker approach to asymptote than when the i value is
smaller.
Finally, although it may
not seem so, Hull's formula also takes into account how much prior learning
has occurred. This is done through the N parameter. Unlike the delta
rule, of course, prior learning involves just the current stimulus and
response, and not multiple stimuli predicting the association. Thus, while
there are some clear differences between the two rules, they are also more
similar than would appear to be the case on first comparing them.
In addition to habit strength,
Hull also posited an intervening variable of drive level, symbolized
as D. The drive level is posited to be related to the amount of
deprivation of a basic biological need the animal has undergone.
Thus, informally, time since being fed translates into drive level (for
the drive of hunger), with a longer time corresponding to a greater
hunger drive. The higher the drive level, the more strongly motivated the
animal is to perform a response that will satisfy the drive. Or put in
slightly different fashion, the higher the drive level, the more value
the reinforcer has. Drive level will always be 0 or greater.
With these two intervening
variables, we are now able to develop a principle that interrelates them.
This is the principle of reaction potential which states how strongly
excited a specific response is in the presence of a given stimulus
and a given level of drive. The excitation is:
SER = D * SHR
The principle states two
essential conditions for a stimulus to excite a response: (1) that
the stimulus and response be associated together (i.e., that habit strength
be above 0), and (2) that the drive level be positive. An animal that is
not hungry will not perform any behavior that has been associated with
quelling that hunger. And in like fashion, an animal that is not fearful
in an avoidance situation (involving a non-zero level of the fear
drive) will not perform an avoidance response to get away from the fear.
In addition to excitation,
however, Hull also discusses two types of inhibition involving not
doing a response. One is conditioned inhibition, and is symbolized
as SIR. As is clear both from the use of the
word conditioned and from the presence of the S and R
subscripts, this type of inhibition involves learning. The other is reactive
inhibition, and is unlearned. It is symbolized as IR
(note the absence of the S subscript!). Reactive inhibition is a
drive state that arises immediately after performing a response: For a
short period of time thereafter, a factor such as fatigue sets in that
makes the response difficult to do, and that tends to result in the animal
resting until reactive inhibition has gone away.
Although reactive inhibition
may seem a concept whose motivation is puzzling, you will see (in the chapter
on extinction and partial reinforcement) that reactive inhibition
is central to the notion of extinction depending on learning. For
now, one piece of evidence that fits with the notion of reactive inhibition
is the spacing effect discussed in Chapter 2. To remind you, massed
practice (in which trials or responses occur in rapid succession) results
in weaker learning or memory than spaced practice (in which there
is more of a breather between trials). From Hull's point of view, the explanation
for this is that reactive inhibition has not completely dissipated in massed
practice. In addition, spontaneous recovery may be explained by
claiming that with time, reactive inhibition decreases to the point that
excitation is slightly stronger, eventuating in a response.
Given the potential presence
of both excitation and inhibition, we may now posit a second principle
that adds in the notion of inhibition. This principle, the principle of
effective reaction potential, involves the notion of algebraic
summation: The net excitation will be equal to excitation minus inhibition.
Net excitation is represented as excitation with a bar over the symbol.
Thus,
___
SER = (D * SHR)
- IR - SIR
If the two types of inhibition sum to a greater value than excitation,
then the response will be inhibited; otherwise (assuming non-zero excitation),
the response will be expressed. Thus, how strongly a response is performed
will depend on both excitation and inhibition. When we add in the many
factors that in addition to learning affect the strength of a response
(drive level and inhibition, in particular), we see a clear distinction
in Hull's system between learning and performance: Performance
is determined by the principle of effective reaction potential,
whereas learning is restricted strictly to SHR.
One more point now becomes
important: the nature of reinforcement. This involves the notion of a need-drive
cycle. Hull claimed that reinforcement was ultimately dependent on
satisfying an organism's biological needs. In time, a state of deprivation
arises that places the animal in a physiological state of need.
This need state gives rise to a psychological state that
may be termed a drive. The psychological state has motive properties
in that it impels the animal towards appetitive responses that will
reduce the drive, and ultimately, reduce the need.
Thus, at some point in time, deprivation of nourishment results
in a need for nourishment that is associated with a hunger drive.
The appetitive responses associated with the hunger drive most directly
include the process of eating and ingesting food, but also
include the search for food. Eating and ingesting food reduce
the drive. With time, the food is broken down, and nutrients are carried
through the blood stream to be absorbed at the cellular level. When that
happens, the need diminishes. Then, in time, the cycle starts over.
Within this cycle, it is
the reduction of the drive that Hull identifies as the reinforcer.
The reason is that it takes too long for the need to go away. Hence, on
the basis of contiguity, a response such as ingesting food can more-or-less
immediately get rid of the hunger drive, but will take longer to have an
effect on the need for food. Thus, in Hull's system, any response that
results in drive reduction will cause the association that triggered that
response (the SHR) to strengthen. If you
go back to the formula for habit strength, you will see that there is no
role assigned to the amount of reinforcement that occurs. That is consistent
with Hull's later approach (in 1952). But in the earlier (1943) model,
he did believe that amount of drive reduction influenced the amount of
strengthening of the association. Thus, in the early version, there was
a principle having to do with amount of reinforcement: Bigger reinforcers
(i.e., greater drive reduction) result in stronger learning.
One more point about the
need-drive cycle: A need can also arise from aversive stimulation rather
than deprivation. Pain administered through shock can cause a need to restore
the organism to a pain-free state, and the pain itself may be associated
with a drive state such as fear.
A further idea we may add
to this collection of theoretical notions is Hull's claim that animals
acquire habit hierarchies. Put simply, in any given situation, a
stimulus may become associated with a number of different responses,
so that it may have links to many responses. According to Hull, which response
it is most likely to make will then depend on which response is
most strongly excited by the principle of effective reaction potential.
Since associations never really weaken in Hull's system, a response that
fails to work in a given situation may acquire some conditioned
inhibition, so that its net excitation (its effective reaction potential)
decreases relative to another response. And a response that does
work will have its habit strength increased, resulting in stronger
net excitation, relative to some other response. Thus, associated with
each stimulus condition are a number of responses that may be ordered in
terms of their relative effective reaction potentials. This ordering constitutes
the hierarchy of available responses. The animal will perform the responses
in order of this hierarchy, when it is in a state of drive, until some
response finally works.
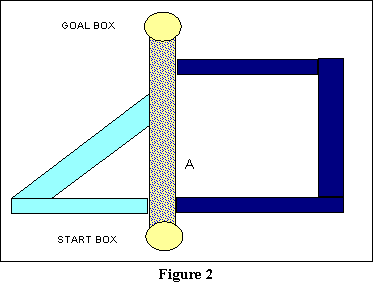 As a sample experiment, relevant to this, consider a sample study by Tolman
and Honzik using a 3-arm maze of the sort represented in Figure
2. In this maze, the start box is the yellow oval at the bottom, and the
chamber to which the animal must run for its reinforcement (the goal box)
is the yellow oval at the top. There are three routes to the goal box:
the route directly between the two ovals (the speckled route); the triangular
route (solid grey in black and white; light blue on a color monitor); and
the rectangular route (dark blue or black, depending on your monitor).
Let us call these three routes Pathways 1, 2, and 3, respectively. Hull's
notion of a habit hierarchy would predict that running down Pathway 1 would
be at the top of the hierarchy associated with being in the start box;
running down Pathway 2 would be the next strongest association; and running
down Pathway 3 would be the weakest. There are several reasons we can use
to justify this predicted ordering, but the most obvious two involve the
effort in making the response, and the delay of reinforcement.
The straight path involves the least effort, and gets the animal
to the food the soonest. The triangular path involves more
effort and a greater delay, and the rectangular path involves yet more
work, and an even longer delay. Thus, following initial exploration of
the maze, we ought to find that our animals generally settle into the routine
of running Pathway 1.
As a sample experiment, relevant to this, consider a sample study by Tolman
and Honzik using a 3-arm maze of the sort represented in Figure
2. In this maze, the start box is the yellow oval at the bottom, and the
chamber to which the animal must run for its reinforcement (the goal box)
is the yellow oval at the top. There are three routes to the goal box:
the route directly between the two ovals (the speckled route); the triangular
route (solid grey in black and white; light blue on a color monitor); and
the rectangular route (dark blue or black, depending on your monitor).
Let us call these three routes Pathways 1, 2, and 3, respectively. Hull's
notion of a habit hierarchy would predict that running down Pathway 1 would
be at the top of the hierarchy associated with being in the start box;
running down Pathway 2 would be the next strongest association; and running
down Pathway 3 would be the weakest. There are several reasons we can use
to justify this predicted ordering, but the most obvious two involve the
effort in making the response, and the delay of reinforcement.
The straight path involves the least effort, and gets the animal
to the food the soonest. The triangular path involves more
effort and a greater delay, and the rectangular path involves yet more
work, and an even longer delay. Thus, following initial exploration of
the maze, we ought to find that our animals generally settle into the routine
of running Pathway 1.
But let us specifically ask
what would happen if, following acquisition, Pathway 1 were blocked at
a point corresponding to, say, A on the figure? If you look at the
maze, you will see that such a blockage occurs after the other two
paths diverge, but before either of them comes back into the central path.
In this case, Hull's habit hierarchy predicts the animal ought to back
up to where the other two paths diverge, and run down Pathway 2, since
it is the next most-favored response on the hierarchy. And that is what
generally does happen.
Other findings consistent
with Hull (in addition to the shape of the acquisition curve, spacing
effect, spontaneous recovery, and choice of response as indicated
by habit hierarchies) include the effects of delay of reinforcement
and amount of deprivation. Because Hull's is a contiguity theory,
reinforcement ought to work at short delays following a response. Grices's
results cited in the previous chapter serve as an example consistent with
this prediction. And because deprivation should translate directly into
drive level, Hull's theory predicts that depriving an animal of food for
a longer period of time should result in more vigorous responding. That
result has also been verified.
The 1952 Version
There were a number of problems
(see below), some of which were addressed in a later statement of the theory.
For the moment, we may briefly identify three problem areas that
resulted in revision of the theory. These areas involved (1) whether drive
reduction was sufficient to account for reinforcement, (2) how contrast
effects could be accounted for in the earlier theory, and (3) the finding
that stimulus intensity seemed to influence behavior.
Let us start with the issue
of drive reduction as constituting reinforcement. Hull became convinced
that drive reduction per se would not work as an account of reinforcement.
That change of heart was due in part to the work that Sheffield and his
colleagues were publishing at the time. To see the problem, let's consider
a sample experiment by Sheffield and Roby. They taught rats a response
using a reinforcer of saccharine. As you may remember from earlier
chapters, rats do indeed react to saccharine. In the absence of any prior
experience with saccharine, they will nevertheless treat it as a primary,
unlearned reinforcer.
Why is this a problem for
Hull's theory? In a nutshell, the problem (acknowledged by Hull) is that
saccharine serves no nutritional value. It can neither satisfy the
need for food, nor the hunger drive. And because it has not been experienced
before by the rat, it is not a learned or secondary reinforcer. Even if
it were (due to generalization, for example), it should readily extinguish
because it fails to satisfy any nutritional need. Hence, the use of saccharine
cannot involve the operation of drive reduction.
How did the theory change
in response to this? Hull handled such findings by altering the focus from
drive reduction to moderation of the drive stimuli. He claimed
that there were stimulus components associated with the various drive states.
When you are hungry, for example, you may experience stomach contractions
and growlings. When you are thirsty, you may experience a sensation of
dryness about the lips (the 'parched, cracked lips' syndrome). In the later
theory, reinforcement occurs when these stimuli are removed or moderated
to less intense levels. Thus, eating saccharine will work because there
is some bulk substance moving into the stomach which 'satisfies' the drive
stimuli associated with an empty stomach.
But what about contrast effects?
As you know from several of the studies mentioned in the previous chapter
(see particularly Crespi's work on incentive contrasts),
a change in the amount of reinforcement will influence behavior after
acquisition of the association. We discussed such effects as evidence for
a distinction between learning and performance, a distinction that Hull's
theory also maintains. But if you look at the variables that affect performance
in the earlier version of the theory, you will find none that is capable
of predicting a contrast effect. Thus, animals in Crespi's experiment who
are shifted from 64 to 16 food pellets immediately respond less
vigorously following the shift. Because associations never weaken in Hull's
system, a change in the size of the reinforcer cannot decrease the
habit strength, but can only result in smaller increases on subsequent
trials, a result at odds with what actually happens in a negative contrast.
Moreover, Crespi's results
also displayed a positive contrast for the group shifted from 4
to 16 pellets (see Figure 3 in the previous chapter): They displayed a
much larger increase in responding than would be expected, according
to Hull's account of how habit strength increases, on this relatively late
conditioning trial. That finding, in turn, suggested that perhaps size
of reinforcer had its primary influence on performance rather than
learning.
To accommodate results such
as these, Hull's theory included two new changes. The first, briefly
discussed above, got rid of the notion that size of reinforcement had anything
to do with how much learning occurred on any given trial. So long as
there was an effective reinforcement (defined in terms of reducing
the drive stimuli, of course), the habit strength increased by a certain
amount. That amount of change was calculated by the formula for
SHR you have already been introduced to: That
formula contains no variable that refers to size of the reinforcement.
And the second change involved
introducing a new intervening variable called incentive motivation,
and symbolized by K. Incentive motivation was an attempt to capture
the notion that bigger reinforcers would result in more vigorous responding,
because they were of greater value to the animal. For food, incentive motivation
could be operationally defined as the amount or weight of the reinforcer.
Greater values of K ought to result in stronger net excitation, whereas
weaker values ought to result in weaker net excitation. Thus, incentive
motivation may be regarded as an addition to the notion of reaction potential,
the principle of amount of excitation. Our revised formula for reaction
potential (and you can add in a similar change for the effective
reaction potential formula) may now be expressed as follows:
SER = D * K * SHR
Note here that very low levels of K should depress responding
whereas high levels should magnify responding. Thus, the formula
can now handle contrast effects involving positive and negative
contrasts. Moreover, when incentive motivation is at 0, then no excitation
will be evident.
One more change is worth
discussing. As in CS intensity effects in classical conditioning, it became
evident that stimulus intensity in instrumental conditioning influenced
responding. Thus, Hull added in yet another intervening variable termed
stimulus-intensity dynamism, symbolized by V. Stimulus intensity
could be non-existent (0), or positive to various levels, with higher levels
generating more excitation. You should be able to predict that such an
effect on performance forms part of the principle of excitation. Hence,
we may now present a reasonably complete formula for how strongly a response
is excited (the principle of reaction potential) as:
SER = D * K * V * SHR
and the formula for effective reaction potential as:
___
SER = (D * K * V * SHR)
- IR - SIR
As you may see from this
latter formula, the relationship between learning and performance in Hull's
later theory turns out to be quite complex. In particular, a minimal level
of drive, incentive motivation, or stimulus intensity will turn off the
expression of the response, as will sufficiently high levels of inhibition.
There were other principles and intervening variables in Hull's system,
but the ones we have discussed should give you a good basis for understanding
and evaluating Hull's approach.
Problems With Hull's Approach
Because Hull's theory was the
most formal, well-defined of the instrumental learning theories, it was
also the one that attracted the most attention. A number of people found
fault with various aspects of the theory. Some of these you already know
about from the previous chapter. However, we will briefly review these
in a more systematic fashion below, so that you may more easily evaluate
the theory. For the sake of convenience, we will divide our discussion
into experiments that examined problems with how Hull's theory treated
responses; experiments that found fault with his notion of
a reinforcer; and experiments that found fault with his conception
of learning.
RESPONSE-ORIENTED ISSUES.
Let us start with the theme of responses. One of the central tenets of
Hulls' theory was that learning involved a habit whereby a stimulus triggered
specific muscle movements. (This may be presented as the issue of the
molecular nature of responding.) As you know from a previously discussed
experiment by Macfarlane, however, animals who learn to run a maze
will later be able to swim it to the goal box. As running and swimming
involve different muscle movements, learning to run should not transfer,
in Hull's system, to learning to swim. Similarly, experiments by Morris
and by Morris, Garrud, Rawlins, and O'Keefe using the Morris
Maze demonstrated that rats who learned to swim in one direction were
able to immediately swim in another direction to get to a hidden platform,
when released from a novel location in the maze. Being released from a
different location should either have involved a stimulus situation so
different as not to trigger any effective response at all, or
the same response of swimming at a certain angle relative to the
point of release (which ought to have resulted in the rat swimming to the
wrong location).
Another issue having to do
with responses concerns the claim (met earlier in classical conditioning:
recall the experiment by Light and Gantt involving temporarily paralyzing
a dog's paw!) by Hull that a physical response has to occur in order for
habit strength to increase. (This may be presented as the issue of the
need to make a response.) But we saw earlier in numerous observational
learning studies that animals could learn by observing others. Different
types of observational learning occurred. One of these involved the construction
of cognitive maps in the absence of a response. For example,
recall the experiment by MacNamara, Long, and Wike in which a group
of rats drawn through a maze learned to run it faster than a group without
this experience. Recall, too, the experiment by Menzel in which
a chimp watching an experimenter hide bananas in a field remembered where
these could be found, but located them in a different order -- hence made
different responses -- than that in which they were hidden. Another type
of observational learning we looked at involved the acquiring of
responses prior to their actual performance. As an example of this
type, recall the Bandura study in which kids learned how to play
with toys by watching a clown play with them, and the Kohn and Dennis
study in which rats learned a discrimination faster when they watched other
rats learn the same discrimination. In both of these experiments, a stimulus-response
association was apparently acquired without the animal actually having had first to
make a response.
A final study which we also
learned about in Chapter 4 is relevant here: the Seward and Levy
study on latent extinction. In this study, animals that were put
through a pre-extinction phase in which they were placed in the goal location
without the usual reinforcement extinguished more rapidly. Although
we have not really discussed Hull's theory of extinction yet (see the next
chapter), it also requires that the animal make a response, since extinction
is a form of learning. In Seward and Levy's experiment, however, the animal
is not making any sort of running response, so that response ought not
to become associated with conditioned inhibition. Thus, the Seward
and Levy study also demonstrates a form of learning that is not dependent
on first performing a certain physical movement.
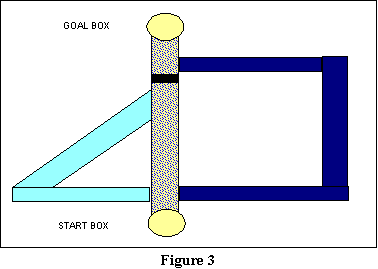 A final issue that concerns Hull's conception of responses has to do with
the order in which an animal will execute responses. We may term this the
issue of whether responses are arranged in a strict habit hierarchy.
A classic experiment by Tolman and Honzik will illustrate this issue.
They took the 3-arm maze used to illustrate the concept of a habit hierarchy
(review Figure 2 and the surrounding discussion), and blocked it at a slightly
different point. Specifically, their maze looked somewhat like that in
Figure 3. The thin black area in the central corridor represents where
the block is located. As you can see, this block also blocks Pathway 2
(the triangular pathway). Thus, on the notion of a strict habit hierarchy,
the rats ought to run down Pathway 1 (the central corridor), hit the barrier,
back up to where the other two pathways diverge, run down Pathway 2 (the
triangular path), hit the barrier again, back up again to where the pathways
diverge, and only then take Pathway 3 (the rectangular path), the
weakest habit in their hierarchy. But of course, that is not what
Tolman and Honzik found. Consistent with Tolman's theory of purpose
behavior built upon knowledge contained in cognitive maps, they found
that their rats avoided Pathway 2, and took Pathway 3 as their second choice.
These rats apparently were able to use their maps to realize that the barrier
also blocked Pathway 2, and thus did not elect that path when given a chance
to do so.
A final issue that concerns Hull's conception of responses has to do with
the order in which an animal will execute responses. We may term this the
issue of whether responses are arranged in a strict habit hierarchy.
A classic experiment by Tolman and Honzik will illustrate this issue.
They took the 3-arm maze used to illustrate the concept of a habit hierarchy
(review Figure 2 and the surrounding discussion), and blocked it at a slightly
different point. Specifically, their maze looked somewhat like that in
Figure 3. The thin black area in the central corridor represents where
the block is located. As you can see, this block also blocks Pathway 2
(the triangular pathway). Thus, on the notion of a strict habit hierarchy,
the rats ought to run down Pathway 1 (the central corridor), hit the barrier,
back up to where the other two pathways diverge, run down Pathway 2 (the
triangular path), hit the barrier again, back up again to where the pathways
diverge, and only then take Pathway 3 (the rectangular path), the
weakest habit in their hierarchy. But of course, that is not what
Tolman and Honzik found. Consistent with Tolman's theory of purpose
behavior built upon knowledge contained in cognitive maps, they found
that their rats avoided Pathway 2, and took Pathway 3 as their second choice.
These rats apparently were able to use their maps to realize that the barrier
also blocked Pathway 2, and thus did not elect that path when given a chance
to do so.
Results such as these are
not always obtained with this type of setup. Keller and Hull, for
example, find that physical features of the maze in addition to where it
is blocked may determine whether the animal will choose Pathway 2 or Pathway
3. But the fact that results like Tolman and Honzik's are sometimes obtained
nevertheless poses a problem for Hull.
REINFORCEMENT-ORIENTED
ISSUES. The next set of problems concerns
the nature of reinforcement. We will start with whether reducing the drive
stimuli (as per Hull's 1952 theory) is all that is needed for reinforcement.
(We may refer to this as the issue of the sufficiency of drive stimuli
moderation.) A series of experiments by Miller and his colleagues is
informative here, but let us consider one study by Miller and Kessen.
They had several groups of rats learn a T-maze. Two groups are of particular
interest: Their reinforcer was milk. However, while one group was allowed
to drink the milk in the normal fashion, the other had the milk pumped
directly to their stomachs. Both groups learned, but the group that drank
in the normal fashion learned more rapidly, and displayed a stronger response.
Since both groups had their stomach-based drive stimuli satisfied, each,
on Hull's theory, ought to have had the same effective reinforcer. But
instead, taste resulted in a stronger effect.
Moreover, Miller and Kessen
ran a third group of rats, but pumped a saline-based solution into their
stomachs, instead of milk. Both 'pumped' groups ought to have had the same
amount of drive reduction from satisfying the drive stimuli, and the same
'negative' consequences, if any, from the process of sending fluids down
an inserted tube. But the group with the saline solution displayed the
worst learning.
Thus, an aspect of reinforcement
that involves tasting the reinforcer in this experiment proved important.
While there certainly was some evidence that satisfying drive stimuli
could serve as a reinforcer, there were other things going on besides,
as is evident from the different results obtained in the three groups.
Perhaps a more serious problem,
however, involves whether reinforcers exist that don't rely on drive stimuli
at all. Certainly in terms of the earlier version of Hull's theory, studies
by Sheffield's group demonstrated reinforcement without drive reduction.
These included the Sheffield and Roby study mentioned above, in
which saccharine was used as a reinforcer, and a study by Sheffield,
Wulff, and Backer (discussed more fully below) in which male rats were
reinforced by being allowed to mount female rats in heat, but were removed
prior to ejaculation (and thus, prior to reduction of the sex drive). Arguably,
however, each of these studies was associated with removal or moderation
of the drive stimuli. More troublesome for Hull's theories were studies
like Butler's (see previous chapter), in which monkeys learned responses
for reinforcers that involved looking into a laboratory, or out on a parking
lot. What are the drive stimuli that get moderated here? Or to take another
example, consider a study by Premack in which young kids learned
a response whose reinforcer was playing a pinball game. The notion of a
pinball drive and pinball drive stimuli does not bear extended scrutiny,
to put it politely.
LEARNING-ORIENTED
ISSUES. Perhaps the most serious set of problems,
however, concerned the issue of when learning would occur, and how it would
progress. As we have seen from the latent learning experiment of
Tolman and Honzik, learning may occur without the presence of any
apparent reinforcement whatsoever, in direct contradiction to Hull's
claim that habit strength depends on a response being followed by a reinforcer.
This could be termed the issue of non-reinforced learning. And in
a related issue, the issue of incremental learning, Voeks
demonstrated that sometimes incremental learning was the exception, rather
than the rule. Following up on Guthrie's approach (see below), Voeks demonstrated
all-or-none learning: Her animals either didn't show an evidence
of an association, or demonstrated evidence that they had acquired the
association at full strength.
In short, while there may
certainly have been some situations in which drive reduction or moderation
of drive stimuli served to influence learning, Hull's limitation of learning
to these situations (and to the acquisition of individual muscle movements)
proved too restrictive.
The theory was in trouble.
B. Sheffield's Consummatory Response Hypothesis
As Sheffield was one of the
first (along with Tolman) to cause Hull to revise his theory, we ought
to briefly describe Sheffield's alternative. His theory, the consummatory
response hypothesis, relied on dividing responses into two sorts: instrumental
responses, and consummatory responses. Instrumental responses,
of course, are those behaviors that are performed to obtain a desired reinforcer,
whereas consummatory responses involve the (instinctive or reflexive) behaviors
associated with satisfying a biological drive. Behaviors involved with
eating or swallowing food, for example, qualify as consummatory responses,
as does a parent bird's regurgitation of food to feed a nestling (although
in this case the consummatory response involves a drive associated with
care of the young). For Sheffield, reinforcement could be identified
with engaging in consummatory behavior, rather than the drive reduction
required in Hull.
As this brief description
makes clear, both Hull and Sheffield tied reinforcement to biological states
associated with drives, although they were quite different in other respects.
Thus, although Hull at one point described the amount or quality of reinforcement
as being dependent on amount of drive reduction, Sheffield equated quality
of reinforcement with vigor of the consummatory response. The more
vigorous the behavior, the better the reinforcement (and learning). Thus,
rats will escape a strong shock more rapidly (more vigorously) than a weak
shock, and will lap up sweeter liquids more vigorously than less sweet
liquids.
As you know, Sheffield
and Roby demonstrated learning using a reinforcer of saccharine. Rats
will engage in vigorous consummation of the saccharine, which is why it
serves as a reinforcer. Moreover, different concentrations of saccharine
(compared to plain water) result in different levels of the consummatory
response, and not surprisingly, different levels of instrumental responding
(recall Kraeling's results with different sucrose concentrations).
So, if we set up a contingency between instrumental and consummatory responding
such that certain instrumental responses will be followed by an opportunity
to engage in a consummatory response, we ought to find (1) that acquisition
of the instrumental behavior occurs, and (2) that it depends on the vigor
of the consummatory response.
A famous experiment illustrating
these simple but compelling ideas was performed by Sheffield, Wulff,
and Backer. We have talked about this experiment briefly, but let us
present it in a bit more detail. This was the study using a female rat
in heat as the reinforcer. Sheffield et al. used rats that were sexually
naive (i.e., that had never mounted a female), and placed them in the start
box of a maze. Presumably, their sex drives were not at high levels
immediately prior to the start of this experiment: The female's pheromones
would have induced a high drive level (so that we see yet another
mechanism, aside from temporal deprivation, by which a drive state
may ensue). And to remind you, they allowed the male rats to mount the
female, but prevented them from ejaculating (i.e., the rats engaged in
a consummatory response that did not lead to drive reduction). So what
happened?
Sheffield and his colleagues
noted that the rats apparently differed in drive level. Those rats who
were little interested in the female (i.e., those rats who did not engage
in vigorous consummatory responding) showed much lowered levels of learning
compared to those who were highly interested. Thus, as predicted, learning
depended on the vigor of the consummatory response, and not the satisfaction
of a drive. In a real sense, vigor of a consummatory response may be taken
as a measure of the extent to which a drive state has been induced.
For our rats who were uninterested in the female, a vigorous consummatory
response did not occur because their sexual drives were not brought up
to a sufficiently high level.
It is an interesting idea,
but not everyone has been able to track a simple correlation between vigor
and learning or performance. And many of the studies that posed problems
for Hull also pose problems for Sheffield. What is the consummatory
response in the Miller and Kessen study in which rats were fed through
a tube, for example? How do we assess a difference in vigor for a saline
solution versus a milk solution piped into a rat's stomach? What is the
consummatory response in Butler's experiment with monkeys? What
consummatory response occurs on the first ten trials with Tolman and
Honzik's latent learning group?
Reinforcement may have multiple
effects and causes, including drive reduction and drive induction. But
results such as those above suggest the presence of additional factors
that may eventuate in reinforcement. We turn next to claims that reinforcers,
at least sometimes, are context dependent.
II. Contextual Reinforcement Theories
In this section, I am including
what might be termed a flexible reinforcement approach. That is, what counts
as a primary reinforcer in one context or set of circumstances will fail
to act as a reinforcer in another. These theories share the property that
reinforcement need not be transituational, in contrast to Skinner's
claim. As such, they each provide at least one explanation for belongingness
effects. In short, sometimes a response (or a stimulus) acts as a reinforcer,
and sometimes it doesn't. Let's see what the various theories have to say
about when something will operate as a reinforcer.
A. Optimal Stimulation Theory
The first theory we will look
at is actually a series of related theories that have been proposed over
time by a number of different people. You may wish to look up a book by
Berlyne and Madsen to sample some of these. They are generally related
also to a notion of drive level. But these theories claim that there is
a certain optimal level of drive or stimulation that the animal seeks to
preserve. The theories are homeostatic in that the animal's behavior
depends on where its current level of stimulation or arousal is. In these
theories, a reinforcer is any event that brings the animal closer to
its optimal level of stimulation. Thus, an overstimulated animal
will be reinforced by a stimulus event that involves a decrease
in arousal, whereas an understimulated animal will be reinforced
by a stimulus event involving the opposite: an increase in
arousal.
The notion of differing arousal
levels may also apply to individuals, as the optimal level will differ
individual to individual. Within the area of personality theory, for example,
some theorists have claimed that extraverts are people who are understimulated
(and thus seek greater stimulation), whereas introverts are overstimulated,
and generally seek decreased stimulation.
In any case, although the
theory can obviously handle both drive reduction and drive induction reinforcers,
it is a difficult theory to test in practice, due to the need to know what
an animal's optimal level of arousal is, and what its current level is.
Obviously, some simple predictions can be made: Depriving an animal of
food for a long enough period should place it in a higher-than-optimal
level of arousal, so that decreases in arousal (as provided by food rewards,
for example), ought to be reinforcing. But even here, things get complicated.
Animals that are hungry are more likely to respond to novel stimuli. That
appears to be the wrong prediction, since novel stimuli increase
the level of stimulation overall.
Still, the theory has the
benefit of making a number of predictions, and thus being easily testable.
We would predict, for example, that mildly hungry animals ought to find
a moderate amount of food more reinforcing than a large amount,
whereas very hungry animals ought to exhibit the reverse effect.
(For moderately hungry animals, a small amount ought to bring them closer
to their optimal levels; for very hungry animals, the large amount ought
to bring them closer.) Moreover, stimulus intensity, novelty,
and complexity do seem to have an effect on arousal, as measured
by aspects of the orienting response. Longer or more intense orienting
responses are associated with greater levels of these three qualities,
as predicted by the theory. Thus, the theory in principle can handle some
of the findings we looked at earlier in which 'non-traditional' reinforcers
were present. Being able to look out on a lab is an increase in stimulation
for monkeys that are understimulated (as in Butler's experiments);
and being able to explore a novel maze qualifies as an increase in stimulation
for, say, Tolman and Honzik's latent learning group. And as you
will see shortly, the theory has some similarity to later work by Timberlake
and Allison (see below).
B. The Premack Principle
If optimal stimulation theory
defines reinforcement in terms of the stimulation provided to an animal,
the next theory concentrates, instead, on what happens while the animal
is responding. In this theory, reinforcement is regarded as the opportunity
to engage in a response for doing some other response. But what makes the
theory a flexible, context-dependent theory is that whether a response
reinforces depends strictly on its strength relative to the other, to-be-learned
response.
The notion, posited by Premack,
is quite simple: Let us observe animal behavior in free-choice situations.
Let us further assume that the relative amount of time the animal devotes
to different responses may serve as a measure of how preferred a response
is. We may then establish the animal's preference ordering of responses.
This ordering will reflect the relative strength of a response,
with the response at the top of the ordering being the most preferred response,
and that at the bottom being the least preferred. The Premack Principle
may then be succinctly stated as follows: Stronger responses will reinforce
weaker responses.
Thus, for any response that
is not at the top or the bottom of the preference ordering, there will
be at least one response that it fails to reinforce, and at least one other
response that it will reinforce. For example, given the following preference
ordering of six responses,
A > B > C > D > E > F
response A will reinforce all the other responses because it is stronger
than all the others, and response F will reinforce none of the others,
because it is weaker than all the others. Response C, however, will reinforce
D, E, or F, but not A, or B. The theory thus finds a natural mechanism
to explain the belongingness effects of the type Shettleworth
found with hamsters (see previous chapter). Indeed, now that we know the
three responses that were not reinforced by food and the three responses
that were, we could test the theory out as an explanation of Shettleworth's
results by making a prediction about what a hamster's preference ordering
would look like. The prediction would be:
(face washing, scent marking, hind leg scratching) >
eating the reinforcer provided by Shettleworth >
(digging, rearing, front paw scraping)
Note particularly that reinforcers
on Premack's account do not have to be tied to biological drive states,
and do not have to involve such activities as eating or drinking. Thus,
as was true of optimal stimulation theory, Premack's approach can handle
'non-traditional' reinforcers such as exploring a maze (which is a response)
or checking out what's happening in the lab (which is also a response).
Here is a sample study that
illustrates the Premack principle. Premack observed first-graders in a
free-choice situation involving candy-dispensing machines (let's call them
gumball machines, for short), and pinball machines. Each child's preference
was established, and the kids were subsequently identified as players
or eaters. Then, 4 groups were set up in which a contingency between
the gumball and pinball responses was established, to determine whether
a child's behavior could be modified. The design of the experiment was
as follows:
Group Preference
Learning Task
1a
player
gumball response followed by chance to pinball
1b
player
pinball response followed by chance to gumball
2a
eater
gumball response followed by chance to pinball
2b
eater
pinball response followed by chance to gumball
In this experiment, the prediction,
of course, was that playing should act as a reinforcer for the players
but not the eaters, and that eating should act as a reinforcer for the
eaters, but not the players. In harmony with this prediction, a congruity
effect was obtained in which the learning that was successful in the
two types of children differed: Which type of learning occurred was congruent
with the child's type. So, only Groups 1a and 2b displayed any increase
in responding on the first machine during the learning task. The other
2 groups exhibited the same amount of responding on the first machine as
they had during the pre-learning session.
Although I have presented
a simple version of the Premack Principle, there is more to it than what
we have discussed so far. In particular, the Premack Principle explains
reinforcement size or quality effects in terms of relative preference.
Thus, to take our example of the preference ordering presented three paragraphs
earlier (6 activities ordered from Response A to Response F), while Response
E will reinforce Response F (since it is stronger), Response A should be
a much better reinforcer because it is so much stronger. As an illustration
of this notion, consider another study by Premack that involved rats learning
to press a lever to get a chance to run in an activity wheel, or to dispense
a certain amount of drinking solution. Premack used 3 different concentrations
of sucrose in the drinking solution (64%, 32%, and 16%), and 2 different
levels of difficulty in running in the activity wheel (it was weighted
with an 80 gram or an 18 gram weight). By observing rats in a free choice
situation involving these 5 responses, he established the following preference
ordering:
16% Drink > 32% Drink > 18 g Run > 64% Drink > 80 g Run
Lever pressing, of course, is considerably lower in the preference ordering.
So, we run an experiment using 5 groups of rats in which one of the 5 responses
above is used as the reinforcer for lever pressing.
Premack found, in accord
with the theory, that the average number of lever responses per 10-minute
session (following learning) depended on which response was used as the
reinforcer. As the second (contingent) response increased in preference,
so did performance of the first (learned) response. Rats allowed a brief
run in a heavily weighted activity wheel pressed the lever about 20 times
per session, but rats allowed a quick drink of the 16% sucrose concentration
pressed the lever about 37 times per session.
Of course, the theory also
applies to punishment. Specifically, Premack's claim is that punishment
involves a situation in which a more preferred response is followed by
the requirement that the animal engage in a less preferred response.
(You should note that this is not what our players and eaters in
Groups 1b and 2a did: They had the opportunity to engage in the
less preferred response following the more preferred response, but they
were not forced to do so.) Premack has done some studies illustrating
that such a setup decreases the amount of time the animal does the
more preferred response, consistent with a punishment-like interpretation.
The same response may thus reinforce a weaker response but punish a
stronger response.
A final experiment will illustrate
one additional feature of this theory. Let us take two activities such
as running in an activity wheel, and drinking. For 2 groups of rats, we
will deprive the animals of activity wheel running for a day; for 2 other
groups, we will deprive them of drinking for a day. That amount of deprivation
ought to change their momentary preferences for drinking versus running.
Let us call the drink-deprived rats drinkers, and the activity-wheel-deprived
rats runners. Our experiment may then be set up as follows:
Group Preference
Learning Task
1a
drinker
running response followed by chance to drink
1b
drinker
drinking response followed by chance to run
2a
runner
running response followed by chance to drink
2b
runner
drinking response followed by chance to run
If you compare this design to the one used for the kids playing pinball
or gumball machines, you will see it is formally identical. And as predicted,
a congruity effect occurs whereby rats deprived of water will treat
water as a reinforcer (and will thus increase their running), and rats
deprived of running will treat running as their reinforcer. A rat's drinking
will not be affected by whether drinking is followed by the opportunity
to engage in running when it is the drinking that has been deprived, and
not the running. Similarly, a rat's running will not be affected by drinking
when running has been deprived. Thus, if we run 2 other control groups
as follows:
Group Preference
Pseudo Learning Task
1c
drinker
drinking response
2c
runner
running response
we should see no difference in amount of drinking between groups 1c
and 1b, and no difference in amount of running between groups 2a and 2c.
In the 'c' groups, we measure baseline drinking or running in free choice
after deprivation, to see how much catching up they do. (That is why this
task is referred to as pseudo learning. There's no real learning going
on here, it's just a control so that we can assess changes from normal
levels in our experimental groups.) In short, as was true with the earlier
study using kids, only Groups 1a and 2b exhibit learning. They will
increase their drinking or running relative to the control groups.
The message in this latter
study is that deprivation will momentarily increase the preference or strength
of the deprived response: Accordingly, an animal's preference ordering
may temporarily change because of deprivation.
C. Equilibrium & Bliss Points
Although the Premack Principle
has appealed to many, it has itself been supplanted due to several apparently
inconsistent predictions. Timberlake and Allison have pointed out
many of the problematic findings here. Perhaps the most direct problem
involves situations in which the Premack Principle wrongly predicts learning.
On occasion, a weaker response will seem to reinforce a stronger response;
and on occasion, a stronger response will not reinforce a weaker
response. Moreover, additional features of the situation come into play
that are not covered by the Premack Principle. The type of learning that
occurs may depend on the relative rate at which each response has to be
performed to get a chance to do the other. Finally, as people like Staddon
and Ettinger have pointed out, some events simply do not seem to qualify
as responses, yet they have the property of moderating the behaviors they
follow. Is a shock, properly speaking, an instrumental response the animal
engages in? Treating it as such appears to stretch the definition of a
response, although it is certainly the case that administration of shock
results in instrumental responses of many sorts.
In order to handle some of
these situations, Timberlake and Allison have developed (separately and
jointly) what is sometimes referred to as the response deprivation hypothesis
(Allison's term). This hypothesis takes off from some of the studies Premack
performed, in which weak responses can be turned into reinforcers of strong
responses through deprivation. The relevant point to be made here, however,
is that many -- if not most -- studies of instrumental learning
have a component of deprivation. Establishing a contingency between two
responses such that one has to be performed in order to get a chance to
do the other often means that the second response is somewhat restricted
or deprived. In the gumball-pinball experiment, for example, players who
had to eat to play were being deprived of playing. Thus, in a modification
of the Premack Principle, the response deprivation hypothesis generalized
the principle to the claim that an animal will perform a non-deprived
or less-deprived activity in order to get a chance to do a more-deprived
activity.
Note the implicit claim of
this principle: If the strong and the weak responses are not deprived,
then the strong response ought not to reinforce the weak response. And
in contrast (as in the activity wheel study of Premack), if the weak response
is deprived, then it will reinforce the strong response. One of
the advantages of such an approach, particularly considering the latter
case, is that we need not try to assess the increase in strength of a weak
response due to deprivation, in order to see whether it is now stronger
than the normally more preferred response. Instead, we need simply assess
which response is the more deprived.
Let us consider an experiment
by Allison and Timberlake. They chose two levels of a saccharine
solution such that their rats displayed a preference for the higher level.
We will refer to these levels as dry and sweet for the sake
of convenience. (Note, however, that a rat's preference for sweet solutions
isn't strictly linear: As you can see from a previous study by Premack,
it is possible to create solutions so intensely sweet that they
are no longer preferred to less sweet solutions). In any case, consistent
with the Premack Principle, Allison and Timberlake verified that their
animals would learn a task involving sipping the dry liquid in order to
sip the sweet liquid. So far, so good. But Allison and Timberlake then
asked another question. Suppose we ask animals to sip the sweet to get
a shot at the dry. Would the animals do it? On Premack's theory, they shouldn't.
But in Allison and Timberlake's experiment, if the rats had to take ten
sips of the sweet to get one sip of the dry, then they actually
displayed learning: In apparent contradiction to Premack, a less preferred
response reinforced a more preferred response.
Why did this happen? The
basic idea behind Timberlake and Allison's approach is that animals in
a free choice situation are in a state of equilibrium: They are
able to engage in various activities at their preferred levels. These various
levels are the bliss points. Or to put it slightly differently,
the bliss points are the levels at which you are happiest. You have a bliss
point for how much ice cream you would like to eat, for example. Being
at the bliss point keeps you at equilibrium. But, being below or above
the bliss point gives you a motive for returning to the bliss point. And
if you consider the implications of being below or above the bliss point
for ice cream, you will see how these states may lead to appetitive or
aversive responding. Being below your bliss point gives you a reason for
doing something that will get you more ice cream. But, being above
(being forced to eat too much ice cream!) will give you a reason
for doing something that lets you beg off having to eat more ice cream.
At this point, for example, you might even offer to go into the kitchen
and start washing dishes, so you don't have to eat more.
Both optimal stimulation
theory and the response deprivation hypothesis involve homeostasis,
whereby an animal or person in a state of disequilibrium attempts
to return to the ideal level. In both, the same outcome may serve
as a reinforcer when the organism is below its ideal level or bliss
point, and as a punisher when it is above. Thus, the approaches
ought to strike you as quite similar.
But how do we explain rats
being willing to take 10 sips of sweet to get one sip of dry? How does
this fit in with the notion of bliss points? Assume, for the moment, that
in a free choice situation involving what to drink, the animal drinks the
sweet stuff 60% of the time, and the dry stuff the other 40% of the time
(these made up figures refer to proportion of drinking choice, not the
animal's overall activities). By forcing it into a situation where it has
to engage in drinking the sweet at 10 times the rate of the dry, we have
effectively forced it into a level below its bliss point for the
dry. Hence, we have given it some motivation for doing something that would
return it to the dry bliss point.
If you have followed the
reasoning so far, however, you will also realize that we have done something
else in this experiment: We have potentially moved the animal far above
its bliss point for the sweet, and thus given it some motivation to decrease
drinking of the sweet liquid. And that demonstrates one of the most powerful
ideas in Timberlake and Allison's approach. There will be a tradeoff
between the response level and the outcome level, if both are out of equilibrium.
In that case, an animal's behavior will tend to reflect an optimization
strategy in which it engages in the two responses at a level that
is closest to their joint bliss points. Thus, while we have been used
to thinking about how learning is defined in terms of moderation of the
response frequency, Timberlake and Allison provide us with a new perspective
in which we also look at moderation of the outcome behavior.
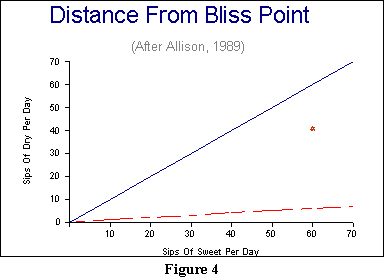 We can illustrate this principle graphically. In Figure 4, we have drawn
a graphical representation corresponding to our hypothetical rat's 60%
preference for sweet. For the sake of argument, let us say that this translates
into 60 sips of sweet per day in free choice, and 40 sips per day of dry.
The orange starburst is the animal's joint bliss point for these two activities.
In contrast, the two lines reflect two different contingencies that we
might set up between sweet and dry. A one-to-one contingency is represented
by the solid blue line, and a 10 sweet-to-1 dry contingency is represented
by the dotted red line. In each case, the closest point on
the line to the starburst is the best the animal can do by way of getting
both responses back to their joint bliss point. And if you draw in the
shortest line from the starburst to the dotted red line, you will see that
it involves taking more than 60 sips of sweet, in agreement with
Allison and Timberlake's finding above.
We can illustrate this principle graphically. In Figure 4, we have drawn
a graphical representation corresponding to our hypothetical rat's 60%
preference for sweet. For the sake of argument, let us say that this translates
into 60 sips of sweet per day in free choice, and 40 sips per day of dry.
The orange starburst is the animal's joint bliss point for these two activities.
In contrast, the two lines reflect two different contingencies that we
might set up between sweet and dry. A one-to-one contingency is represented
by the solid blue line, and a 10 sweet-to-1 dry contingency is represented
by the dotted red line. In each case, the closest point on
the line to the starburst is the best the animal can do by way of getting
both responses back to their joint bliss point. And if you draw in the
shortest line from the starburst to the dotted red line, you will see that
it involves taking more than 60 sips of sweet, in agreement with
Allison and Timberlake's finding above.
This work, along with other
work on relative choice such as Herrnstein's Matching Law and optimal
foraging theory, represents an interesting trend towards analyzing
instrumental behavior in terms of economics. Economic theories also
discuss the various tradeoffs involved in choices, and present mathematical
models concerned with the relative costs and benefits of such choices,
and how one might optimize the cost-benefit ratios. It is a very different
and a very useful way of looking at the nature of learning and reinforcement.
III. Non-Reinforcement Approaches
We come, finally, to theories
in which reinforcement does not determine whether an association forms
between a stimulus and a response. In these approaches, learning occurs
regardless of the presence or the absence of reinforcers. The question
thus posed is, why do reinforcers (and punishers) seem to have such drastic
effects? We will see some very different answers to this question. According
to Guthrie's contiguity theory, stimuli that are traditionally classified
as reinforcers simply help prevent the animal from acquiring new learning
that interferes with previous learning. In the other approaches, by way
of contrast, reinforcement acts as feedback that motivates performance.
Hence, memories of what has happened on previous occasions when an animal
did this or that response may be evaluated to assess the desirability of
various outcomes.
A. Guthrie's Contiguity Theory
Let's start with Guthrie. We
have briefly discussed Guthrie in an earlier chapter. To reiterate the
major point, Guthrie is a contiguity theorist but not a reinforcement
theorist. His basic idea is that there is some independent probability
that a response formed in the presence of a stimulus will forge an association
with it. That probability is completely unaffected by the occurrence of
a subsequent event involving what is normally called reinforcement or punishment.
Guthrie's writings were rather
informal, and sometimes ambiguous. One of his students, Voeks, formalized
them into a system of principles. Three of these principles are of particular
interest to us. These are the principle of association, the principle
of postremity, and the principle of response probability. You
have already been introduced to the principle of association. Voeks
added that a stimulus presented within half a second of the animal making
a response would likely be associated with that response. (For comparison,
review Guthrie's principle of conditioning presented in the previous chapter.)
There is a point about this
principle that may not be obvious to you. According to both Guthrie and
Voeks, when an association forms, it is a full strength. Thus, learning
is not incremental in this approach. Instead, the learning ought
to be sudden (occurring on a given trial). Such learning is referred
to as all-or-none learning. As we will see in Chapter 7, all-or-none
learning is also posited in hypothesis-testing approaches to
discrimination learning. These approaches claim that animals adopt a hypothesis
about what to pay attention to in a discrimination. They operate according
to a win-stay lose-shift strategy: If the hypothesis works, keep
it; if it doesn't, replace it with another. Thus, on this account, there
ought to come a trial on which the animal selects the proper hypothesis.
When that happens, the learning occurs, and is complete. Attentional hypothesis-testing
theories and Guthrian theories agree on this sudden and complete nature
of learning, although they claim radically different processes underlying
the learning.
Figure 5 presents an example
of what an individual learning curve might look like. Prior to learning,
there ought to be some relatively random behavior, some of which may sometimes
by chance involve doing the correct response, and some of which may not,
so long as the association has not formed. When this random behavior is
averaged over small sessions, the result ought to be a 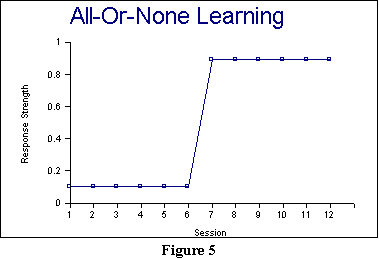 relatively
flat baseline level of responding (but that might be slightly above 0 due
to chance fluctuations). Then (in this case, in Session 7), the association
forms, and thereafter the animal ought to have the association in full
strength ,so long as no other association forms that competes with
it: see the next principle below.
relatively
flat baseline level of responding (but that might be slightly above 0 due
to chance fluctuations). Then (in this case, in Session 7), the association
forms, and thereafter the animal ought to have the association in full
strength ,so long as no other association forms that competes with
it: see the next principle below.
If you compare this acquisition
curve to the incremental curve in Figure 1 or to Figures 3 and 4 in the
chapter on classical conditioning (Chapter 2), you will see that the all-or-none
curve appears to differ from the idealized and actual obtained diminishing
returns curves. However, there are several reasons for why such a difference
may be more apparent than real. One of these is that learning curves are
typically averaged over a group of animals. Because the animals learn at
different rates, they will form the association on different trials. Thus,
a curve averaged over a group of animals includes both animals
who have formed the association on a given trial, and animals
who have not. Since the probability increases that more and more animals
get the association as trials progress, the average goes up, giving the
appearance of gradual, continuous, incremental learning. Hence, an important
lesson to be learned from Guthrie's approach is that we ought to look
at what individual animals do, and not just at what the group as a
whole does: Averaged learning may not represent the type of learning found
with individuals.
The principle of postremity
represents one of the more lasting contributions of a Guthrian approach.
This principle handles the fact that multiple responses may become
associated with a single stimulus, since learning is constantly occurring.
According to this principle, if there are incompatible responses
linked to the same stimulus, then the more recent response is the one that
will be expressed.
Guthrie laid particular stress
on the notion of response competition. Learning is continually occurring,
but new learning constantly overwrites or interferes with old learning.
Hence, the learning may be difficult to see simply because response competition
is likely to hide it from us. The notion of response competition has come
to play a major role in theories of extinction, and in some of the
theories of interference-based forgetting in humans. Since learning
seems to occur when a reinforcer is present, Guthrie will argue
that the role of the so-called reinforcer is really to minimize the possibility
of response competition, making it more likely that we see the same response
repeatedly. We will return to this shortly.
The third principle, the
principle of response probability, states that the probability of
a response in a given context is dependent on the proportion of
stimuli in that context that are associated with the response. This, too,
has had a major impact on later stimulus sampling theories of learning
and memory. Stimulus sampling theories (Estes's theory of learning
is a major example of these, although Bower's sampling theory of
memory also deserves mention) claim that we sample some of the many stimuli
(or their features) in our environment, so that learning and recall are
best described as probabilistic, depending on the samples. But for
now, concentrate on the fact that a response may become conditioned to
a large number of stimuli. It won't become conditioned to all or most of
them on the same trial, of course. But, if we can prevent competing responses
from occurring, then over the course of a number of trials, more and more
stimuli in the environment will become connected with the response, resulting
in a greater and greater probability that the response will be excited.
Thus, you now see a second reason why learning can appear to be
gradual: The probability of exciting a response increases over trials because
of an increase in the number of associations with the response, even though
the critical association that the experimenter tends to be interested in
may have formed at full strength on one of these trials.
So how does this relate to
reinforcement? We, the experimenters, have defined a certain response we
want to see, and whose increased probability of expression we will take
to be evidence of learning. Let us assume this response is lever pressing.
When the animal makes that response, we provide it with a novel stimulus
that we have termed a reinforcer. Any response it makes following the lever
press is thus, by the principle of association, likely to be associated
with the novel stimulus, and not the previous stimulus complex
that triggered the response. Thus, our animal will not overwrite the lever
press response with a potentially competing response, because subsequent
responses are not connected to the same stimulus as the lever press.
Competing responses require connection to the same stimulus; the provision
of a so-called reinforcer has prevented that.
What about punishment? We
can extend the analysis to aversive stimulation by pointing out that such
stimulation inevitably increases the animal's behavioral level, resulting
in a number of responses. As most of these are likely to compete with the
original response (running away is incompatible with a number of responses,
for example), we stop seeing the original response. Moreover, higher levels
of punishers result in greater behavioral expression, increasing the probability
of acquiring a competing response early.
Why aren't punishers like
reinforcers? That is, why don't punishers create novel stimuli to which
a potentially competing response conditions? If you analyze what typically
happens with punishers and reinforcers, the latter involve an external
stimulus (food; drink; etc.) which results in appetitive or consummatory
activity, but the former typically do not involve a change in the external
stimuli. Shock administered through the floor grid of a Skinner box doesn't
involve changing what the floor grid looks like. And also, aversive stimuli
tend to trigger immediate reflexive defense mechanisms, as you know from
our discussion in a previous chapter of Bolles and SSDRs.
The presence of food or drink leads to appetitive behavior which,
once consummation starts, may result in reflexive behaviors such as drooling.
But the presence of punishment doesn't have this delay built in between
the onset of the outcome and the reflexive behavior. In that sense, they
ought not to act the same way.
Thus, given this overview
of Guthrie's theory, let us look at a few predictions. An advantage of
the theory, of course, is that it can potentially handle learning situations
(like Tolman and Honzik) in which there is no reinforcer. Voeks
set up some experiments to test the theory more explicitly, however. Based
on the principle of response probability, she argued that an environment
in which the stimuli were kept identical trial to trial would result in
faster expression of a response than one in which the stimuli were allowed
to vary. When stimuli vary, of course, the probability that most of them
are associated with the response grows much more slowly, because of the
constant introduction of new stimuli. Consistent with the theory, she found
faster expression in the constant environment. (Note that use of the word
expression: The results appear to suggest faster learning,
but since learning is all-or-none, that is really not the case.) Moreover,
when she examined the individual learning curves, they did appear to be
all-or-none, rather than incremental.
Another study that fits in
with Guthrie's notion of response competition was introduced in the last
chapter: This is the study by Fowler and Miller. To remind you,
they shocked rats on their rear paws after entering a goal box, or on their
front paws while entering the goal box. The latter event should have caused
backwards motion, which is incompatible with the forward motion
of running to the goal. The animals shocked on their front paws extinguished
more rapidly, as Guthrie would have predicted.
Similarly, Baum examined
the extinction of fear in animals who were prevented from making
a learned avoidance response to a danger situation. One group of animals
was simply not allowed to avoid or escape, so that they were exposed to
the conditioned danger signals, but without the accompanying shock. This
type of extinction procedure (presence of the conditioned aversive CS,
but absence of the aversive UCS) is referred to as flooding. Rats
flooded in a chamber they can't escape from tend to become motionless.
A second group was also flooded with danger signals, but they were forced
to move about. Within a Guthrian framework, forcing animals to make responses
should increase the probability of a competing response, resulting
in quicker extinction of avoidance. That is what happened.
Subsequent work claimed that
incremental learning was sometimes obtained at the individual level (and
that incremental theories could be modified to predict something that looked
very like all-or-none learning). In addition, problems with the single
mechanism of response competition were found (although response competition
will indeed prove to have an important role in extinction: see the next
chapter). Thus, the Seward and Levy study on latent extinction,
for example, is difficult to reconcile with the notion of response competition,
since the latent extinction appears to occur in a different stimulus complex
(the goal box) than the one conditioned to initiating the response of running.
And finally, some of the
findings regarding the nature of reinforcement don't seem to fit Guthrie's
theory elegantly. How are we to account for the fact that different concentrations
of sucrose or saccharine appear to have different effects on the response,
for example? Will a higher concentration of saccharine count as an internal
stimulus that makes acquiring a competing response less likely? Or to take
the Miller and Kessen study, how are we to account for the fact
that different fluids pumped directly into the stomach have different effects?
Are there noticeable stimulus properties by which these fluids differ
when not tasted or ingested in the usual manner, so that they act as different
internal stimuli?
As these caveats demonstrate,
Guthrie's theory itself did not survive unscathed. Nevertheless, the ideas
he expressed were original enough that they influenced or became part of
many later theories.
B. Observational Learning Theory
A very different approach is
to be found in theorists who adopted an observational learning approach.
We have already discussed one of these theorists in the previous chapter:
Edward Chace Tolman. We will take as a further example of
this work the learning theory of Albert Bandura, although we will
not discuss Bandura's theory at all in full detail. His is a theory that
extends to and focuses on personality and social psychology, and we do
it less than full justice by concentrating on the segment of it relevant
to the issues in this chapter. Consider that an invitation to sample Bandura's
more recent writings.
I have already mentioned
that Bandura in some sense represents one of Tolman's intellectual heirs.
He is perhaps most widely known for his work on whether children learn
aggression from watching violent shows on television. In a famous study
by Bandura, Ross, and Ross, several groups of kids in a nursery
school were matched for level of aggression. One group saw an adult play
aggressively with some toys. Among the toys was a "BoBo" doll: a weighted
punching bag doll that could be knocked down, and would return to upright
position to be knocked down again. The adult knocked the doll down repeatedly;
threw it in the air several times; and hit it with a hammer. A second group
saw a film of this behavior. A third group, the control group, saw none
of the above. Then, the kids were sent in to a room with some really neat
toys (much neater than the BoBo doll), played with them for a bit, and
then were stopped from playing with them any further, in order to experimentally
induce frustration.
We will see in the next chapter
that Amsel's theory of extinction claims in part that frustration
causes an increase in behavioral level, thus enabling the possibility
of learning responses that compete with the original, learned response
(as per Guthrie). Among the consequences of frustration that we
often see is an increase in aggression. This is what Bandura et
al. were interested in. When the kids had to play with the other toys (including
the BoBo doll), would we see any evidence that they had learned how to
play aggressively? In fact, all three groups displayed an increase in aggressive
behavior, but the increase was much larger for the two groups who saw the
adult's aggressive play. In fact, it was about double the level
of the control group's aggressive play. Moreover, the two groups who saw
the adult play with the BoBo doll displayed the same type of aggressive
behavior (hitting it with a hammer; throwing it in the air) as the
model, in contrast to the control group. Thus, the children had
learned to emit certain behaviors by simply observing another person perform
those acts.
In a follow-up study by Bandura,
another three groups of children watched a movie of a clown playing in
a room full of toys. In this film, the clown also spends a lot of time
playing with the BoBo doll. Besides punching it down and throwing it up
in the air, he straddles it once it is down, takes a hammer, hits it on
the nose with the hammer, and utters comments such as "knock 'em, sock
'em, wowee!" (I am going on memory for the comments, by the way: I saw
this tape a long time ago, and those are the ones -- perhaps falsely --
that stick in my mind.) The film is identical for the three groups of children
up to this point: a lot of aggressive play of this sort. However, each
group views a different ending.
One group may be referred
to as the neutral group. The film fades out on the clown's play.
A second group is what Bandura called the vicarious reinforcement group.
They see some additional footage in which an adult authority figure enters
the toy room and rewards the clown for the way in which he was playing.
A third group, the vicarious punishment group, sees the adult punish
the clown for how he played. And the question Bandura asked, of course,
was what would happen when each of the children was placed in the toy room.
How would they play with the BoBo doll?
In brief, the neutral group
and the vicarious reinforcement group displayed the same behaviors as the
clown, including hitting the BoBo doll with the hammer, and in some cases,
uttering some of the same comments. In contrast, the vicarious punishment
group played in a very different fashion. However, once the experimenter
asked the children in this group to show him what the clown had done, they
also performed the same aggressive responses. Thus, all groups had learned
the responses by observing, but whether the responses were emitted or withheld
depended on what happened to the clown.
These two studies exhibit
several major features of Bandura's observational learning approach. First,
observational learning can include imitative behavior: We can acquire
responses by watching others perform them. Second, there is a learning-performance
distinction in this approach, as there is in many others: What is learned
need not be what is expressed: The outcomes associated with different behaviors
will determine their probability of expression. Third, the child need not
first perform the response for learning to occur, nor need the
child directly experience a reinforcing or punishing outcome
associated with the response. Observing these events in others is sufficient:
Observing them in others provides the child with the cognitive knowledge
or information about the likely consequences of an outcome.
Bandura's study reminds me
of a visit I had with my sister and her kids years ago, when they were
3, 5, and 7. As an uncle, I had a reputation with the niblings (my term
for nieces and nephews; it goes along with siblings) for doing magic tricks.
One day, as a joke, I did the following 'magic trick:' I said, "Watch closely!"
I then lowered a towel to cover my legs, slipped one foot out of its shoe,
raised that leg behind me, and then slowly raised the towel up to slightly
below the knee, to show two shoes and one leg. "Ta da!" I said. I then
lowered the towel, and re-raised it to show I had gotten my leg back. The
older kids got the joke, but the three-year-old simply stared, apparently
uncomprehendingly, at this somewhat 'sophisticated' performance. Sure enough,
several hours later, at dinner, she trooped in with a towel and proceeded
to give the same performance.
Imitative behavior as an
aspect of observational learning actually has a very venerable tradition.
Both Thorndike and Watson asked whether this type of behavior
would be found in animals, and answered the question in the negative. Thorndike,
for example, allowed cats to watch other cats learn to escape from his
puzzleboxes, but found no evidence of faster learning in the observers.
Thus, imitation through observational learning was essentially ignored
for many years. Dollard and Miller brought the possibility back
into play by arguing that humans and animals could be reinforced for imitating
others, and that this would essentially be no different than reinforcing
them for making any other sort of a response. But note that this
approach required the reinforcement-based assumption that a certain type
of response (imitation) would be immediately followed by a consequence
(reinforcement or punishment). We now know that animals may indeed learn
from observing others (recall the experiments by Menzel and by Kohn
and Dennis, for example), and that Dollard and Miller were simply wrong
in claiming that such observation relied upon the presence of an immediate
reinforcer. In any case, Tolman claimed that learning could occur through
simple observation, and Bandura seconds that notion.
More formally, Bandura notes
that observational learning is not simply imitation. Rather, it involves
the acquisition of information about consequences. Thus, the vicarious
punishment group in the study above failed to imitate because of what they
had learned. But there is also more to it than this. In addition to the
possibility of acquiring new responses or behaviors by seeing others
perform them, and in addition to the inhibition or disinhibition
of those responses depending on knowledge of likely outcomes, there is
also a type of priming effect or facilitation whereby seeing
someone do something that is already in your behavioral repertoire
makes it more likely that you will engage in the same response. Regarding
inhibition and disinhibition, a negative outcome associated
with an observed response will tend to inhibit that response (as in the
vicarious punishment group), whereas a positive or non-negative
outcome will tend to disinhibit the response (as in the vicarious reinforcement
group). The notion of disinhibition here in part reflects Bandura's concern
with learning aggression: Seeing someone else act aggressively may tend
to disinhibit our aggressive behaviors.
Although Bandura does use
phrases such as vicarious reinforcement and vicarious punishment, you should
not think that punishment or reinforcement are necessary for learning in
his theory. They indeed constitute an additional element of learning, but
do so by providing information. Learning occurs regardless of vicarious
punishment or reinforcement. So, the theory is a non-reinforcement theory,
and moreover, a non-associational, informational approach (a representation-level
theory). The presence of outcomes associated with observed behaviors
simply provides the observer with information about the contingencies
between a response and an outcome. Evaluating those contingencies and the
relative desirability of the outcome is the additional process that determines
performance.
Finally, we will end our
discussion of Bandura by pointing out that he establishes four requirements
for observational learning to occur (especially to the extent that it results
in imitation). First, the observer must be paying attention to the
relevant behaviors of the model, and to the outcomes. Second, these must
be successfully stored in the observer's memory system. In
humans, they may be stored as images, or they may be stored as
verbal descriptions. Third, the observer must be capable of producing
the response. Observing a gifted concern pianist play Mozart will not
help a non-musician perform the same piece the next day. Behavior that
is too complicated and that relies on too high a level of skill of the
many component parts will likely not be acquired or successfully
imitated. Rather, we imitate things we are potentially capable of doing;
and in so doing, we use our memories to compare what we do with
what we saw earlier. Hence, observational learning often involves a component
of refining an imitative response over time through practice
and comparison with a remembered performance observed perhaps
much earlier. And fourth, there has to be some motivation to perform
the behavior. Some aspect of that motivation is given in part, of course,
by whether the behavior is associated with vicarious reinforcement or vicarious
punishment.
We have discussed just instrumental
behavior, but Bandura extends the notion of observational learning to classical
conditioning, as well. In any case, since Bandura's is an admittedly expectancy-based
approach, let us consider some other work on expectancy.
C. Expectancy Theories
To remind you, theories of expectancies
(such as Tolman's), in general, claim that the role of an outcome
provides feedback concerning the value or desirability of
the response. Expectancies are built on contingencies. As you may remember
from our discussion involving Rescorla's contingency approach, expectancies
serve the function of allowing animals to predict future consequences.
In instrumental conditioning, expectancies involve knowing that a certain
response is paired with a certain outcome, and the stimulus conditions
under which such pairings occur. We will later distinguish true cognitive
expectancy theories from more associational approaches, but for now let
us look at some more studies involving expectancies.
We will start with some studies
involving appetitive outcomes.
Approach Learning
In 1970, Trapold asked
an interesting question about expectancies. Suppose we set up a serial
choice discrimination procedure in which one of two stimuli is present,
and the animal needs to perform different responses depending on which
stimulus is before it. For example, in the presence of S1, it
will need to perform R1 to get a reinforcer; but if S2
is present instead, then it will need to perform R2, to get
a reinforcer. We may represent this schematically as follows:
S1 ---> R1
S2 ---> R2
What would happen, Trapold
asked, if we used different reinforcers for these two situations,
instead of the same reinforcer, as was often done up until that point?
(Use of the same reinforcer is referred to as the common outcomes procedure.)
From a non-expectancy, traditional approach, two reinforcers of otherwise
equal value ought to have effects identical to use of the same reinforcer,
as the reinforcer in a traditional associationist approach simply moderates
the S-R link (the strength of the habit). But, from an expectancy-based
approach in which an outcome is an integral part of what an animal
learns about a situation, Trapold reasoned that having different outcomes
ought to have an effect of a certain sort. Before describing what that
effect might be, let us first schematically diagram the expectancies. Using
a system like that introduced in discussing Tolman's theory in the previous
chapter, the situation in which the same reinforcer is used (the common
outcomes procedure) involves the following two expectancies (which
we will call E1 and E2):
E1: S1 R1 ---> O1
E2: S2 R2 ---> O1
But now let us systematically
use different reinforcers (the differential outcomes procedure).
In this latter case, the expectancies would be:
E1: S1 R1 ---> O1
E2: S2 R2 ---> O2
Note that if the
outcome is represented along with the stimulus-response link in the animal's
memory, then the differential outcomes procedure ought to result
in faster learning: The expectancies are more different, and
thus less likely to be confused with one another. And that is what Trapold
found. Contrary to traditional claims that a reinforcement perhaps operates
on (but does not become a part of) the association that constitutes learning,
there was some clear evidence here that the reinforcer was also represented
as part of the learned complex. Such a claim, of course, comports perfectly
with Bandura's and Tolman's approaches.
A number of studies have
now found this effect of reinforcement differentiation. It occurs
not only when the reinforcers are physically different, but as Carlson
and Wielkiewicz show in their studies, when the reinforcers differ
only in amount, or in how long they are delayed following a response. Very
precise information about the nature of reinforcement thus appears to be
acquired in the course of learning.
Another study in which a
similar finding occurs involves the area of acquired stimulus equivalence.
Here, a bit like sensory preconditioning, there will be an attempt
to equate two stimuli to see whether they act as functional equivalents
in setting the occasion for a response. As this is rather abstract, let's
look at a specific study by Peterson.
Peterson looked at discrimination
learning in pigeons. These animals were faced with three keys. The two
keys on the outside differed in that one had a horizontal line over it,
whereas the other had a vertical line over it. The center key first lit
up in a white color. That was the signal for the pigeon to peck it. The
center key subsequently changed color to either red or green. If it changed
to red, then the pigeon had to peck the vertical-line key for an outcome
(e.g., food). But if it changed to green, then the pigeon had to peck the
other key (the horizontal line) for an outcome. In one group, different
outcomes were used (food versus a tone), but a mixed outcomes procedure
was used with another group. (In the mixed outcomes procedure, either reinforcer
can occur after either response; which reinforcer actually appears is determined
randomly.) There were actually more groups, but we will concentrate on
these. Thus, schematically, the expectancies for the differential outcomes
group should have been:
E1: Sred Rvertical ---> Ofood
E2: Sgreen Rhorizontal ---> Otone
Next, Peterson established
a training phase in which a peck at the white key would change it either
to a projected circle, or a projected triangle, following which the animal
would receive the food or the tone. In this phase, the pigeon did not peck
at one of the two side keys (the horizontal or vertical keys); they remained
unlit. Again, some pigeons received a differential outcomes procedure
(in which the circle was always followed by food, and the triangle by the
tone), and others received a mixed outcomes procedure (in which
the pairing was random). Thus, looking at all these possibilities, we have
the following schematic representation of learning for our various training
combinations:
Group Color Task
2nd Task
1
E1: Sred Rvertical ---> Ofood
E3: Scircle ---> Ofood
E2: Sgreen Rhorizontal ---> Otone
E4: Striangle ---> Otone
2
E1: Sred Rvertical ---> Ofood
E3: Scircle ---> Ofood/Otone
E2: Sgreen Rhorizontal ---> Otone
E4: Striangle ---> Ofood/Otone
3
E1: Sred Rvertical ---> Ofood/Otone
E3: Scircle ---> Ofood
E2: Sgreen Rhorizontal ---> Ofood/Otone
E4: Striangle ---> Otone
4
E1: Sred Rvertical ---> Ofood/Otone
E3: Scircle ---> Ofood/Otone
E2: Sgreen Rhorizontal ---> Ofood/Otone
E4: Striangle ---> Ofood/Otone
To help you digest this somewhat
complicated experiment, note that Groups 1 and 2 had reinforcement differentiation
on the first task, but Groups 3 and 4 did not. Note also that the expectancies
for the second task were different in Groups 1 and 3, but not 2
and 4. And of course, the question that Peterson asked was what would happen
in these four groups when pecking the white key would change it to a circle
or a triangle, and the two side keys would come on, requiring
a further peck for the outcome?
If you look at Group 1, you
will see that both the circle and the red light had a single food outcome
in their expectancies, whereas both the triangle and the green light had
a single tone outcome. Peterson found that this procedure resulted in Group
1 showing near perfect first-session learning in this new task. They had
apparently learned that the circle and red light were equivalent, so that
they needed relatively little additional training to peck the vertical
key in the presence of the circle. Similarly, they needed little additional
training to peck the horizontal key when the triangle came on. In other
words, they were able to coordinate their expectancies to derive the following
new expectancies:
E5: Scircle Rvertical ---> Ofood
E6: Striangle Rhorizontal ---> Otone
The other groups required
more extensive training to acquire these expectancies. Or to put this in
a nutshell, coordinating two stimuli with the same outcome led to the
pigeon making a response in the presence of one stimulus that it had earlier
made in the presence of another. What is novel about this study on
acquired stimulus equivalence is that the equivalence was based on the
common outcome, thus again providing evidence that information about the
outcome constitutes part of what is learned and stored.
Avoidance Learning
Contingency theory has been
one of the major theories accounting for avoidance learning. In avoidance
learning, to remind you, the animal makes a response that avoids the primary
punisher in the first place. Contingency theory stands in marked contrast
to the major associational theory of avoidance learning, Mowrer's Two
Factor Theory of Avoidance Learning. Let us start with a brief description
of Mowrer.
We'll first dispense with
what the two factors are. These are classical conditioning and operant
conditioning. According to Mowrer, a good behaviorist believing in
a positivist approach would have a major problem with avoidance
learning. This problem, the problem of foresight, appears to implicate
an organism being aware of future consequences, and taking action
to avoid those consequences. The problem for a good behaviorist, of course,
is that foresight involves prediction -- cognitive states referring
to knowledge rather than reactive associations that get triggered
by the presence of the proper stimuli. So the relevant issue for a positivist
behaviorist is how to explain avoidance learning without having to rely
on foresight.
It turns out that there is
a clever way of doing this. Mower pointed out that avoidance learning situations
typically include a component of classical conditioning. Specifically,
in the initial trials when the animal has not yet acquired the avoidance
response, the various stimulus cues that are present become associated
with the aversive stimulus. Thus, through classical conditioning, the general
environment associated with the shock (or whatever aversive stimulus is
being used) becomes a secondary punisher. For example, a light presented
5 seconds before the shock comes on serves as the CS for the UCS of the
shock, and as such, takes on some of the negative qualities of the shock.
Among these may be fear (recall Miller's study of acquired fear).
According to Mowrer, so-called avoidance learning is then due to acquisition
of an instrumental response that reduces the animal's acquired fear. Put
another way, the animal learns a response that gets it away from the nasty
conditioned stimulus.
On this account, the second
factor (instrumental conditioning) involves use of negative reinforcement:
Escaping from the newly conditioned secondary punisher acts as a reinforcer,
so the animal learns to escape the CS. So, on this account, avoidance learning
is really escape learning: But, it is escape from the CS, rather
than the UCS. And as such, it need involve no appeal to foresight. We need
not think the animal capable of predicting the oncoming shock; we need
only think the animal desirous of getting away from some situation involving
stimulus cues that increase the animal's fear.
One more point, while we
are on the subject of Mowrer. Mowrer's general approach arose from Hull's
theory. So, some aspects of that theory such as drive level were
assumed to apply here, as well. Specifically, the performance of the avoidance
response was assumed to be dependent on the presence of a non-zero fear
drive: So long as the fear-of-the-CS drive was non-negative, excitation
would also be non-negative.
Other theories have adopted
differing accounts of avoidance learning. Bolles's SSDR theory,
for example, claims that much avoidance involves animals performing species-specific,
preprogrammed responses in the presence of danger signals, and so
ought not to count as learning at all. Rather, the animal acquires information
about danger signals that will trigger these SSDRs, and safety
signals in which 'normal' learning may occur. Several studies by
Blanchard and Blanchard, for example, show that rats will freeze in
situations where running cannot get them out of danger, but will run in
other situations, if that response is an option. Certainly, as we have
mentioned earlier, avoidance responses that are similar to SSDRs may be
acquired quite easily and rapidly, in contrast to other responses that
conflict with SSDRs.
Yet other theories adopt
a contingency-based or expectancy-based approach. Thus, Seligman and
Johnston have claimed that avoidance learning requires animals to conjoin
two expectancies into a single contingency. One expectancy is that
performing a response of a certain sort results in no shock. The
other is that not performing that response results in obtaining a shock.
Thus, by stumbling on the response that will successfully escape (and later
avoid) the shock, the animal comes to build these expectancies, and coordinate
them. Once they have been coordinated, then the animal is once more in
control of its environment, insofar as experiencing an unpleasant
outcome is concerned.
The cognitive expectancy
theory of avoidance learning, in particular, makes some very different
claims about what an animal experiences during training than does the two-factor
theory. In particular, so long as the animal has failed to coordinate
the two expectancies into a contingency, the animal ought to experience
fear because of the expectancy that tells it shock is coming in the environment
in which it now finds itself. But once that coordination occurs, the fear
ought to extinguish. The shock is now predictable on the basis of whether
the animal performs the response, rather than just the stimulus cues present
before the shock. Thus, those cues become occasion setters signaling when
the animal ought to execute the avoidance response. In contrast, because
of the close tie-in of Mowrer's theory to the Hullian notion of drive level,
animals in the latter are assumed to be fearful so long as they are still
performing an avoidance response.
A number of studies have
examined these differing claims. In one famous study, Black monitored
the heart rates of dogs during extinction of avoidance learning. The Mowrer
theory would seem to predict a close correlation between heart rate and
the process of extinction: As heart rate returns to less elevated, normal
levels, so should the avoidance response become weaker. Such an approach
assumes, of course, that elevated heart rates provide an adequate measure
of how fearful an animal is. But contrary to what Mowrer would predict
(and consistent with Seligman and Johnston), heart rate returned to normal
much, much sooner than avoidance extinguished. In fact, avoidance took
about five times longer to cease.
In another study, Kamin,
Brimer, and Black attempted to measure fear by use of the suppression
ratio (see the chapters on classical conditioning). If the stimulus
cues present during avoidance training become conditioned to fear as Mowrer
would predict, then they ought to interfere with on-going instrumental
appetitive responding in a very different context (i.e., a version of the
summation test we used in classical conditioning to determine whether
true inhibition occurred). Kamin et al. found that the CS signaling the
approaching shock did successfully suppress in a summation test
when animals had undergone a small number of avoidance learning
trials, but had no suppressive effects when animals had undergone
a large number of trials. Such a finding, of course, is exactly
what Seligman and Johnston's theory predicts.
Finally, consider an experiment
by Herrnstein and Hineline using rats. In their study, animals received
a number of shocks at fairly quick intervals. If the animal pressed a bar,
then the next shock would occur after a longer interval of time,
thus effectively reducing the total number of shocks the rat was receiving.
After that delayed shock, however, the shocks would revert to the rapid
rate unless the rat continued pressing the bar. Avoidance in this
case involved making a series of responses to keep on a reduced rate of
punishment.
Seligman and Johnston, of
course, can easily handle this in terms of learning a contingency involving
bar pressing and rate of shock. But a problem this study poses for Mowrer
is the following: What is the CS in this experiment that enables classical
conditioning of fear (Mowrer's first factor)? And how does the animal
get away from that CS to experience negative reinforcement when it
bar presses (Mowrer's second factor)?
In contrast to Mowrer's theory,
Seligman and Johnston also include the various outcomes (shock; a place
of safety) in their account of what an animal learns. Predicting consequences
is of central importance in their account of avoidance learning. They thus
embrace foresight, rather than view it as a problem. Foresight (the
ability to predict) is one of the critical characteristics of an
expectancy theory. Evaluating that knowledge and determining a course of
action contingent upon it is another critical characteristic. The
work of Bandura, Tolman, and Seligman and Johnston encompasses both of
these characteristics.
IV. A Note On Expectancy-Based Versus Habit-Based Behavior
A major distinction that has
been made, sometimes implicitly, at other times, explicitly, between contingency
and associational theories is that contingency theories include outcomes
as part of what gets coded in memory. Is this a fair distinction? It turns
out that distinguishing expectancies from associations may be quite difficult,
and may turn on how, precisely, one defines these two. Traditionally, stimulus-response
theories were peripheral rather than central, and did not
include associative links with an outcome. But many modern cognitive theories
are also based on associations amongst events. The associations
in this case are central, rather than peripheral, and certainly
may include links with outcomes. Rescorla's work is a prime example:
He has conducted a great deal of research (much of it involving devaluation
studies) showing that we carry response-outcome and stimulus-outcome
associations in a memory system (recall the Colwill and Rescorla
study discussed in the previous chapter, for example). Thus, central
associations may constitute the knowledge or information on which an animal
bases its actions.
Let us briefly return to
the Peterson study to see how a central associative model might
predict the learned stimulus equivalence result Peterson obtained. To remind
you, two stimuli (vertical and circle, for example) were both associated
with the same outcome. Previously, pigeons had learned to peck at a lit
vertical key when a red key was lit to get some grain. On other trials,
pecking at a white key caused a circle to light up briefly (but not the
vertical key), followed by the grain reinforcement. Later, the pigeons
pecked the lit vertical key when the circle lit up. (Similar results occurred
with a tone: You may wish to review the training for Group 1 above). Using
Group 1's training, we can now proceed to identify the associative links
these animals acquired as being something like the following:
(1) Sred ------
Rvertical ------
Ofood
Scircle ------
and
(2) Sgreen ------
Rhorizontal ------
Otone
Striangle ------
In each of the above, the
top associative links represent the learning from the first phase, and
the bottom link represents the learning from the second phase. Because
a common outcome was used in both, these two phases may be connected through
that common outcome in memory. Thus, presence of a circle should
cause activation to travel through its links, and at least some
of that activation should also reach the response. In this way,
an associational model including outcome links can explain the apparently
'rapid' learning of the Group 1 pigeons in the third phase of the experiment.
But in addition, there is
another feature of classical associationist models that might be used to
distinguish between expectancy and habit-based approaches to behavior.
As Hull's term habit implies, associations in traditional stimulus-response
theories suggest fairly rigid, inflexible behavior. In contrast, theories
such as Bandura's appear to rely on a more dynamic, flexible cognitive
system in which evaluations based on current knowledge guide behavior.
Is there any way to distinguish among these?
The answer is that there
might be. In one of the major current theories of human learning, ACT*,
John Anderson discusses two different types of memory systems. One
is Declarative Memory, and the other is Procedural Memory.
Declarative Memory is the type of memory humans have for information that
can be declared. It includes factual knowledge such as "Halloween comes
on October 31," and perhaps mistaken beliefs such as "Aliens regularly
visit Roswell, New Mexico." Such contents are often referred to as know-that
knowledge, because you are aware of a certain content, and can express
it. Thus, if you can say that "I know that P" where P is
any proposition or statement, then you are expressing declarative knowledge.
Procedural Memory, on the other hand, includes what Anderson terms production
rules: If-Then rules that execute an action (the then
part) whenever a certain condition (the if part) occurs in
working memory. These rules are sometimes called know-how knowledge:
You know how to ride a bike, but expressing that knowledge declaratively
will prove enormously difficult.
As you might gather from
this very brief introduction to Anderson's work, production rules are relatively
inflexible, and operate automatically. They thus seem good candidates for
the types of automatic actions captured by the term habit. Some
external or internal stimulus configurations active in working memory automatically
cause a production to fire. Contrary to stimulus-response theories, the
productions need not involve overt responses. But, productions may
be regarded as condition-action associations that are triggered strictly
by activating the condition part of the association (much as a stimulus-response
association is supposed to be triggered by presenting the stimulus).
Declarative Memory, in contrast,
includes all sorts of associations amongst different facts, events, and
beliefs. It is more flexible in that various processes can operate on these
associations to yield behavior. The associations in some sense serve as
a database or repository of knowledge, and one of the questions
Anderson and his colleagues ask is what processes operate over that database
under which circumstances?
The basic types of structures
Anderson posits in Declarative Memory include images, lists,
and propositions. Images, of course, ought to remind you of Tolman's
cognitive maps. But propositions are also of interest to us here.
These are like elementary ideas that involve a topic about which something
may be asserted. In a very real sense, an expectancy could be expressed
as a proposition, although it need not be. Thus, an animal that expects
to get fed when it presses a bar in the presence of a tone could have this
knowledge represented declaratively as a proposition, or procedurally
as a condition-action production.
The issue I am raising here,
of course, is whether animals (besides our own species) have declarative
knowledge. It is possible that they have just procedural knowledge. But,
it seems to me that many of the claims and theories we have looked at regarding
expectancies imply a declarative component: The animal knows-that,
rather than knows-how. And the question this raises is whether we
can come up with a proper test to determine what type of knowledge animals
really acquire.
As of this writing, one of
the graduate students in the University of Southwestern Louisiana's Center
for Advanced Computer Studies, Chris Prince, is collecting data
relevant to this question. Prince's rats are learning to navigate a radial
maze according to certain principles. Some rats have to learn, for example,
the following rule:
When there is food in the south arm, then there will be food in the east
arm.
If this is stored as a production
rule, then it should be non-reversible: Being in the south arm is
the condition that will activate the production, but being in the
east arm will not. If the rule is stored as a declarative
rule, however, then any part of the rule could be activated, and activation
should then travel to and bring up the other parts of the rule. So, the
question Prince's data is relevant to is whether rats who have learned
this rule will run to the south arm when they are first placed in
the east arm. Will they be able to reverse their paths? (Note the
similarity to the cognitive map studies of Tolman and Honzik.)
As of this writing, the answer
appears to be "no." Many additional studies will be required to verify
this result and its explanation, of course. But in any case, the results
we've looked at in this and the last chapter now strongly suggest that
we need to evaluate learning in terms of an animal's memory systems, and
the type of information likely to be stored in them.
Learning need not depend
on reinforcement or punishment, but when those events occur, they become
part of the memory, and thus subsequently affect behavior. Whether such
knowledge in animals can be characterized as declarative is perhaps
one of the most interesting and important questions learning theorists
can now explore.
Partial Bibliography
Allison, J. (1983). Behavioral economics. NY: Praeger.
Allison, J. (1989). The nature of reinforcement. In S.B. Klein &
R.R. Mowrer (Eds.), Contemporary learning theories: Instrumental conditioning
and the impact of biological constraints on learning (13-39). NJ: Erlbaum.
Allison, J., & Timberlake, W. (1974). Instrumental and contingent
saccharine-licking in rats: Response deprivation and reinforcement. Learning
and Motivation, 5, 231-247.
Amsel, A. (1958). The role of frustrative nonreward in noncontinuous
reward situations. Psychological Bulletin, 55, 102-119.
Anderson, J.R. (1983). The architecture of cognition. MA: Harvard
U. Press.
Bandura, A. (1965). Influence of models' reinforcement contingencies
on the acquisition of imitative responses. Journal of Personality and
Social Psychology, 1, 589-595.
Bandura, A., Ross, D., & Ross, S. (1961). Transmission of aggression
through imitation of aggressive models. Journal of Abnormal and Social
Psychology, 63, 575-582.
Bandura, A., Ross, D., & Ross, S. (1963). Imitation of film-mediated
aggressive models. Journal of Abnormal and Social Psychology, 66,
3-11.
Baum, M. (1970). Extinction of avoidance responding through response
prevention (flooding). Psychological Bulletin, 74, 276-284.
Berlyne, D.E., & Madsen, K.B. (Eds.) (1973). Pleasure, reward,
preference: Their nature, determinants, and role in behavior. NY: Academic.
Black, A.H. (1959). Heart rate changes during avoidance learning in
dogs. Canadian Journal of Psychology, 13, 229-242.
Blanchard, R.J., & Blanchard, D.C. (1969). Crouching as an index
of fear. Journal of Comparative and Physiological Psychology, 67,
370-375.
Bolles, R.C. (1970). Species-specific defense reactions and avoidance
learning. Psychological Review, 77, 32-48.
Bower, G.H.
Butler, R.A. (1953). Discrimination learning by rhesus monkeys to visual
exploration motive. Journal of Comparative and Physiological Psychology,
46, 95-98.
Carlson, J.G., & Wielkiewicz, R.M. (1972). Delay of reinforcement
in instrumental discrimination learning of rats. Journal of Comparative
and Physiological Psychology, 81, 365-370.
Carlson, J.G., & Wielkiewicz, R.M. (1976). Mediators of the effects
of magnitude of reinforcement. Learning and Motivation, 7, 184-196.
Colwill, R.M., & Rescorla, R.A. (1985). Postconditioning devaluation
of a reinforcer affects instrumental responding. Journal of Experimental
Psychology: Animal Behavior Processes, 11, 120-132.
Crespi, L.P. (1942). Quantitative variation in incentive and performance
in the white rat. American Journal of Psychology, 55, 467-517.
Dollard, J.C., & Miller, N.E. (1950). Personality and psychotherapy.
NY: McGraw-Hill.
Estes, W.K. (1955). Statistical theory of spontaneous recovery and regression.
Psychological Review, 62, 145-154.
Estes, W.K. (1959). The statistical approach to learning theory. In
S. Kock (Ed.), Psychology: A study of science Vol. 2 (). NY: McGraw-Hill.
Fowler, H., & Miller, N.E. (1963). Facilitation and inhibition of
runway performance by hind- and forepaw shock of various intensities. Journal
of Comparative and Physiological Psychology, 56, 801-806.
Grice, G.R. (1948). The relation of secondary reinforcement to delayed
reward in visual discrimination learning. Journal of Experimental Psychology,
38, 1-16.
Guthrie, E.R. (1952 ). The psychology of learning. (Revised edition)
NY: Harper & Row.
Herrnstein, R.J., & Hineline, P.N. (1966). Negative reinforcement
as shock frequency reduction. Journal of the Experimental Analysis of
Behavior, 9, 421-430.
Hull, C.L. (1943). Principles of behavior. NY: Appleton-Century-Crofts.
Hull, C.L. (1952). A behavior system. New Haven: Yale.
Kamin, L.J., Brimer, C.J., & Black, A.H. (1963). Conditioned suppression
as a monitor of fear of the CS in the course of avoidance training. Journal
of Comparative and Physiological Psychology, 56, 497-501.
Keller, F.S., & Hull, L.M. (1936). Another "insight" experiment.
Journal of Genetic Psychology, 48, 484-489.
Kohn, B., & Dennis, M. (1972). Observation and discrimination learning
in the rat: Specific and nonspecific effects. Journal of Comparative
and Physiological Psychology, 78, 292-296.
Light, J.S., & Gantt, W.H. (1936). Essential part of reflex arc
for establishment of conditioned reflex. Formation of conditioned reflex
after exclusion of motor peripheral end. Journal of Comparative Psychology,
21, 19-36.
Macfarlane, D.A. (1930). The role of kinesthesis in maze learning. California
University Publication Psychology, 4, 277-305.
McNamara, H.J., Long, J.B., & Wike, F.L. (1956). Learning without
response under two conditions of external cues. Journal of Comparative
and Physiological Psychology, 49, .
Menzel, E.W. (1978). Cognitive mapping in chimpanzees. In S.H. Hulse,
H. Fowler, & W.K. Honig (Eds.), Cognitive processes in animal behavior
(375-422). NJ: Erlbaum.
Miller, N.E., & Kessen, M. C. (1952). Reward effects of food via
stomach fistula compared with those of food via mouth. Journal of Comparative
and Physiological Psychology, 45,555-564.
Morris, R.G.M. (1981). Spatial localization does not require the presence
of local cues. Learning and Motivation, 12, 239-260.
Morris, R.G.M., Garrud, P., Rawlins, J.N.P., & O'Keefe, W.
Mowrer, O.H. (1947). On the dual nature of learning -- A reinterpretation
of "conditioning" and "problem-solving." Harvard Educational Review,
17, 102-148.
Peterson, G.B. (1984). How expectancies guide behavior. In H.L. Roitblat,
T.G. Bever, & H.S. Terrace (Eds.), Animal cognition (135-148).
NJ: Erlbaum.
Premack, D. (1959). Toward empirical behavior laws: I. Positive reinforcement.
Psychological Review, 66, 219-233.
Premack, D. (1962). Reversibility of the reinforcement relation.
Science, 136, 255-257.
Premack, D. (1962). Predictions of the comparative reinforcement values
of running and drinking. Science, 139, 1062-1063.
Seligman, M.E.P., & Johnston, J.C. (1973). A cognitive theory of
avoidance learning. In F.J. McGuigan & D.B. Lumsdens (Eds.), Contemporary
approaches to conditioning and learning (69-110). Washingron, DC: Winston.
Seward, J.P., & Levy, N. (1949). Sign learning as a factor in extinction.
Journal of Experimental Psychology, 39, 660-668.
Sheffield, F.D. (1966). A drive-induction theory of reinforcement. In
R.N. Haber (Ed.), Current research and theory in motivation (98-111).
NY: Holt, Rinehart, & Winston.
Sheffield, F.D., & Roby, T.D. (1950). Reward value of a nonnutritive
sweet taste. Journal of Comparative and Physiological Psychology, 43,
471-481.
Sheffield, F.D., Wulff, J.J., & Backer, R. (1951). Reward value
of copulation without sex-drive reduction. Journal of Comparative and
Physiological Psychology, 44, 3-8.
Shettleworth, S.J. (1975). Reinforcement and the organization of behavior
in golden hamsters: Hunger, environment, and food reinforcement. Journal
of Experimental Psychology: Animal Behavior Processes, 1, 56-87.
Skinner, B.F. (1938). The behavior of organisms: An experimental
analysis. NY: Appleton-Century-Crofts.
Staddon, J.E.R., & Ettinger, R.H. (1989). Learning: An introduction
to the principles of adaptive behavior. CA: Harcourt, Brace, Jovanovich.
Timberlake, W. (1980). A molar equilibrium theory of learned performance.
In G.H. Bower (Ed.), The psychology of learning and motivation Vol.
14 (). NY: Academic.
Timberlake, W. , & Allison, J. (1974). Response deprivation: An
empirical approach to instrumental performance. Psychological Review,
81, 146-164.
Tolman, E. C. (1932). Purposive behavior in animals and men.
NY: Century.
Tolman, E.C., & Honzik, C.H. (1930a). "Insight" in rats. University
of California Publications in Psychology, 4, 215-232.
Tolman, E.C., & Honzik, C.H. (1930b). Introduction and removal of
reward and maze performance in rats. University of Californbia Publications
in Psychology, 4, 257-275.
Trapold, M.A. (1970). Are expectancies based upon different positive
reinforcing events discriminably different? Learning and Motivation,
1, 129-140.
Voeks, V.W. (1950). Formalization and clarification of a theory of learning.
Journal of Psychology, 30, 341-363.
1. Chapter © 1998 by Claude G. Cech